Curso de Python - Introducir datos, control de excepciones, trabajar con archivos
Bienvenidos al nuevo post del curso de Python, al terminar este post ya sabrás como introducir datos por el teclado, cómo gestionar el control de excepciones y mostrar lo que te interesa según el error y sobre todo, trabajar con archivos de texto.
Obtener datos introducidos por el usuario
Tenemos una función que es input() y podemos solicitar al usuario que introduzca un dato y que este se almacene en una variable, esto nos puede ayudar a dinamizar los programas interactuando con los usuarios:
input('Aquí va un mensaje')
NOTA: Los datos introducidos se almacenan como un str, por lo que si quieres almacenar datos tipo float, int tendrás que usar la función de conversión que hemos hablado en el apartado de Tipos de datos en Python.
Vamos hacer este ejemplo:
nombre = input("¿Cómo te llamas? ")
edad = int(input("¿Qué edad tienes? "))
print("Me llamo %s y tengo %i años." % (nombre,edad))
Imprimirá un resultado como:
¿Cómo te llamas? Alvaro
¿Qué edad tienes? 26
Me llamo Álvaro y tengo 26 años.
Control de excepciones
¿Qué ocurre si queremos ejecutar un código y depende de una serie de datos que no se han inicializado? No pasa nada, tenemos un mecanismo que controla las excepciones.
try-except
try:
# Bloque de código que se probará antes de ejecutar
except:
# Bloque de código que se ejecutará si ocurre algún error.
Por ejemplo:
try:
print(a)
except:
print("Hubo un problema.")
Esto nos imprimirá Hubo un problema. pero no nos dice en ningún momento dónde está el error. Evidentemente, el error es que la variable a no contiene ningún tipo de valor. Pero, ¿Qué ocurre si quiero personalizar estos errores y mostrar información según convenga?
No pasa nada, podemos añadir excepciones por error, por ejemplo, si la variable a no existía, podemos crear una excepción que permita decir que no existe porque no está creada de la siguiente forma.
- Primero identificamos como se llama el error en Python:
print(A)
Traceback (most recent call last):
File "/tmp/untitled0.py", line 9, in <module>
print(a)
NameError: name 'a' is not defined
El nombre del error que tenemos que utilizar es NameError.
- Definimos el
try-exceptde la siguiente manera:
try:
print(a)
except NameError:
print("La variable no se ha asignao, por favor, revisa el programa.")
except:
print("Hubo un problema, contacte con el desarrollador de la aplicación.")
¿Se pueden definir múltiples errores y que impiman un mensaje? Sí que se puede, esto además nos permite ahorrar mucho código.
try:
pass
except(NameError, TypeError, ValueError):
pass
except:
pass
También podemos usar un alias e imprimir solo el mensaje de error:
try:
print(a)
except(NameError, TypeError, ValueError) as EstoEsUnError:
print(EstoEsUnError)
except:
pass
¿Para qué nos sirve esto? Para tener un mayor control en la validación e impresión de nuestro código. EstoEsUnError imprimirá: NameError: name 'a' is not defined, con este str podemos iniciar una validación on if-elif-else.
with
with es un método que permite realizar acciones que posteriormente necesitan limpiarse para que no queden restos en memoria, un ejemplo muy común y extendido es cuando se trabaja con archivos.
with open('nombreArchivo.ext', modo') as fichero:
# Bloque de código
Cuando abrimos el archivo de esta forma, aunque hayan problemas con el archivo, este termina cerrándose y dejando de existir en la memoria. Sin embargo, si trabajamos con el archivo de la siguiente forma, el archivo quedará en la memoria de forma casi indefinida en el tiempo generando datos basura:
fichero = open('nombreArchivo.ext','modo')
Además, de que hay que cerrarlo debidamente:
fichero.close()
En el siguiente punto trabajaremos más con los archivos, no nos alarmemos.
Puedes consultar más información sobre este apartado en este hilo de la documentación.
Trabajando con archivos en Python
¿Qué podemos hacer en Python con los archivos? ¿Podemos trabajar con ellos?
La cuestión es que sí, podemos abrir, leer, escribir o crear y eliminar archivos, las operaciones básicas que nos deja hacer un SO si estuvieramos en una shell como bash o zsh.
Abriendo un archivo
La sintaxis que se utiliza es:
fichero = open("ruta del archivo", modo)
La sintaxis correcta,que debe usarse y que utilizaremos en estos ejemplos es:
with open("ruta del archivo", modo) as nombreFichero:
# Bloque de código
| Modo | Descripción |
|---|---|
r |
Lectura, es el valor por defecto, abre el archivo para que se pueda leer y da un error si el archivo no existe. |
a |
Abre un archivo para agregarle información al final, si no existe el archivo lo crea. |
w |
Sobreescribe cualquier contendio que haya en el archivo que esté abierto y/o crea el archivo si no existe. |
x |
Crea el archivo, si devuelve error quiere decir que ya existe. |
Leer archivo
Creamos este archivo:
$ cd /home/$USER/
$ cat << EOF >> hola.txt
> Hola Mundo
> EOF
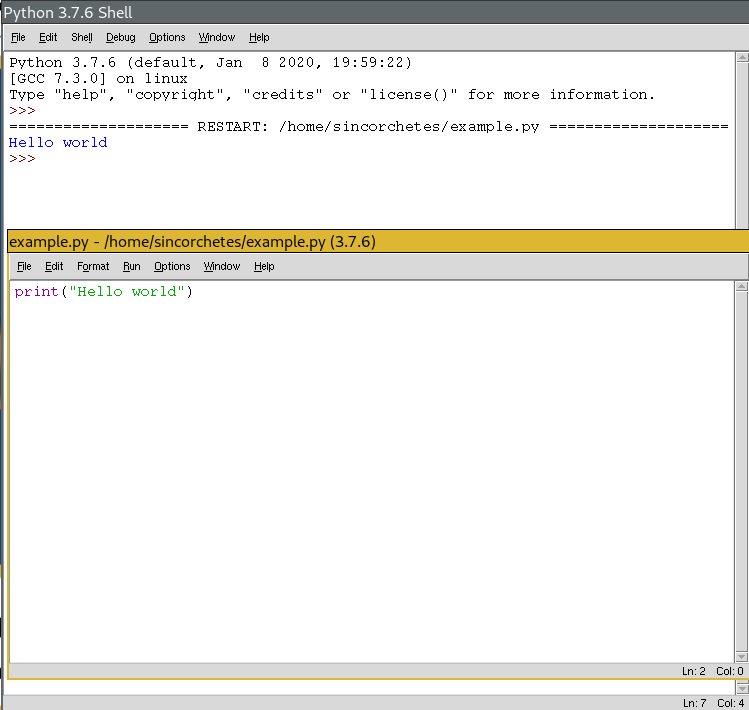
Si hacemos un cat hola.txt nos mostrará Hola Mundo.
Bien, abrimos el archivo con Python
>>> with open("hola.txt","r") as fichero:
>>> fichero.read()
Hola Mundo
Este método también permite decirle que nos imprima los n caracteres del principio del texto con .read(4).
Devuelve una línea
Si tenemos un archivo con más líneas, podemos imprimirlas con .readline() en vez de .read(). Sin embargo, si queremos imprimir mas líneas, tenemos que llamar varias veces al método.
>>> fichero.readline()
>>> fichero.readline()
Leer el archivo completo
Con ayuda de un bucle for lo hacemos:
>>> with open("ejemplo.txt", "r") as fichero:
>>> for linea in fichero:
>>> print(linea)
Creando un archivo nuevo
Si el archivo existe, dará error.
>>> with open("ejemplo.txt", "x") as fichero:
Cuando terminemos de escribir en un archivo, lo cerramos para que no quede en memoria.
fichero.close()
Añadir información al archivo
En esta línea añadimos el siguiente texto.
>>> with open("hola.txt","a") as fichero:
>>> fichero.write("Esta es una línea de ejemplo")
Cuando terminemos de escribir en un archivo, lo cerramos para que no quede en memoria.
fichero.close()
Sobreescribir en el archivo
Sobreescribimos el archivo si lo abrimos con el modo w:
>>> with open("hola.txt","w") as fichero:
>>> fichero.write("Te he sobreescrito el contenido con esta línea")
Cuando terminemos de escribir en un archivo, lo cerramos para que no quede en memoria.
fichero.close()
Eliminar un archivo
Hay que importar un módulo llamado os:
import os
os.remove("hola.txt")




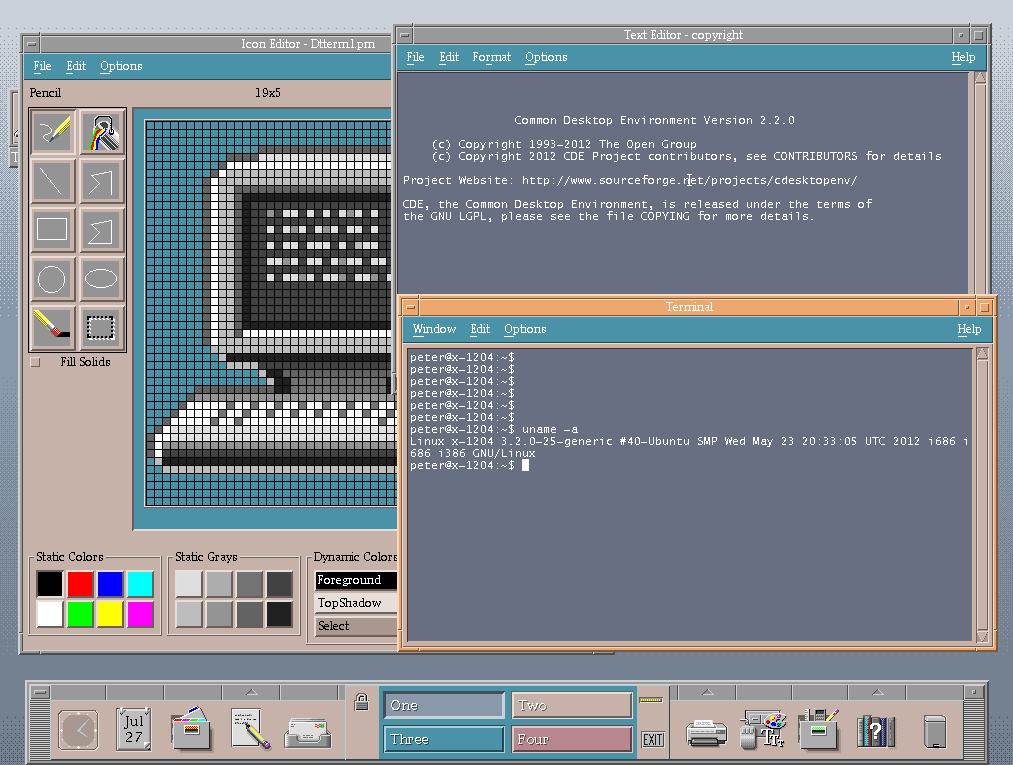 Common Desktop Environment, fue un entorno gráfico para UNIX que fue
desarrollado por empresas de gran hincampié tecnológico como HP, IBM, Novell
y Sun (comprada por Oracle) viendo su primera versión en junio de 1993 de la
mano de HP, IBM, SunSoft y USL(Unix System Laboratories). Estos elaboraron un
proyecto en común repartiéndose las tareas para llevar a cabo diferentes
objetivos hasta llegar a su primera versión del escritorio. Posteriormente, se
fueron involucrando más empresas en su desarrollo. No obstante, estuvo unos años en el mercado
hasta que GNOME y KDE les arrebató su posicionamiento.
Common Desktop Environment, fue un entorno gráfico para UNIX que fue
desarrollado por empresas de gran hincampié tecnológico como HP, IBM, Novell
y Sun (comprada por Oracle) viendo su primera versión en junio de 1993 de la
mano de HP, IBM, SunSoft y USL(Unix System Laboratories). Estos elaboraron un
proyecto en común repartiéndose las tareas para llevar a cabo diferentes
objetivos hasta llegar a su primera versión del escritorio. Posteriormente, se
fueron involucrando más empresas en su desarrollo. No obstante, estuvo unos años en el mercado
hasta que GNOME y KDE les arrebató su posicionamiento.  GNOME (GNU Network Object Model Environment) traducido al español como Entorno
de Modelo de Objeto de Red GNU, un nombre no tan amigable como sus siglas fue
desarrollado por Miguel de Icaza y Federico Mena el 15 de agosto de 1997 como alternativa a KDE (ahora Plasma) para sistemas operativos UNIX-like tipo BSD, Linux, o UNIX como esSolaris (antes SunOS).
GNOME (GNU Network Object Model Environment) traducido al español como Entorno
de Modelo de Objeto de Red GNU, un nombre no tan amigable como sus siglas fue
desarrollado por Miguel de Icaza y Federico Mena el 15 de agosto de 1997 como alternativa a KDE (ahora Plasma) para sistemas operativos UNIX-like tipo BSD, Linux, o UNIX como esSolaris (antes SunOS). KDE fue el primer entorno de escritorio para sistemas UNIX-like que nació en
octubre de 1996 de la mano de un programador alemán llamado Matthias Ettrich que
buscaba básicamente una interfaz gráfica que unificáse todos los sistemas UNIX
imitando el entorno de escritorio CDE.
KDE fue el primer entorno de escritorio para sistemas UNIX-like que nació en
octubre de 1996 de la mano de un programador alemán llamado Matthias Ettrich que
buscaba básicamente una interfaz gráfica que unificáse todos los sistemas UNIX
imitando el entorno de escritorio CDE. MATE es un fork de GNOME que salió el 19 de agosto de 2011 como muestra del descontento de la nueva versión de GNOME 3 debido a que reducía muchísimo la personalización del entorno de escritorio, consumía mucho más, y tenía otro tipo de funcionalidades y características no muy transigentes. Este proyecto fue desarrollado por un desarrollador argenito de Archlinux llamado Germán Perugorría conocido en la comunidad del software libre como Perberos para continuar el desarrollo de este entorno de escritorio. Que por cierto, es el que nosotros utilizamos. El nombre proviene de la hierba Mate muy común en Argentina para tomar.
MATE es un fork de GNOME que salió el 19 de agosto de 2011 como muestra del descontento de la nueva versión de GNOME 3 debido a que reducía muchísimo la personalización del entorno de escritorio, consumía mucho más, y tenía otro tipo de funcionalidades y características no muy transigentes. Este proyecto fue desarrollado por un desarrollador argenito de Archlinux llamado Germán Perugorría conocido en la comunidad del software libre como Perberos para continuar el desarrollo de este entorno de escritorio. Que por cierto, es el que nosotros utilizamos. El nombre proviene de la hierba Mate muy común en Argentina para tomar. XFCE se caracteriza por ser un entorno de escritorio muy liviano y ligero ya que
ese eran sus dos objetivos cuando se desarrolló. La primera versión se liberó en
1996 de la mano de Olivier Fourdan. Este utiliza las bibliotecas de GTK+ para el
desarrollo de sus programas gráficos.
XFCE se caracteriza por ser un entorno de escritorio muy liviano y ligero ya que
ese eran sus dos objetivos cuando se desarrolló. La primera versión se liberó en
1996 de la mano de Olivier Fourdan. Este utiliza las bibliotecas de GTK+ para el
desarrollo de sus programas gráficos. Este fue un entorno de escritorio también como el anterior, cuyo objetivo era
proveer a un PC de una suite de herramientas gráficas que permitieran trabajar
consumiendo lo más mínimo de un ordenador. Su primera versión fue liberada en
2006 por Hong Jen Yee. Actualmente tiene su desarrollo parado, ya que se
sustituyó por LXQt.
Este fue un entorno de escritorio también como el anterior, cuyo objetivo era
proveer a un PC de una suite de herramientas gráficas que permitieran trabajar
consumiendo lo más mínimo de un ordenador. Su primera versión fue liberada en
2006 por Hong Jen Yee. Actualmente tiene su desarrollo parado, ya que se
sustituyó por LXQt. Es la continuación del proyecto LXDE como entorno de escritorio. El anterior
hacia uso de librerías GTK+, LXQT hace uso de Qt ya que al parecer al creador de
LXDE no le terminó de convencer GTK+. Su objetivo y finalidad son el mismo que
en LXDE.
Es la continuación del proyecto LXDE como entorno de escritorio. El anterior
hacia uso de librerías GTK+, LXQT hace uso de Qt ya que al parecer al creador de
LXDE no le terminó de convencer GTK+. Su objetivo y finalidad son el mismo que
en LXDE. Fue un entorno de escritorio desarrollado con las bibiliotecas Qt en 2010, no
obstante, el equipo de Razor-Qt empezó a colaborar con el creador de LXDE
originando el entorno anteriori dando origen a la primera versión en julio del
2014.
Fue un entorno de escritorio desarrollado con las bibiliotecas Qt en 2010, no
obstante, el equipo de Razor-Qt empezó a colaborar con el creador de LXDE
originando el entorno anteriori dando origen a la primera versión en julio del
2014. Sugar es un entorno de escritorio que nació con el objetivo de crear una
interfaz muy intuitiva para aquell@s niñ@s que no podían acceder a la tecnología
puntera de países del primer mundo. Creada por Sugar Labs en mayo del 2016,
como entorno para el proyecto OLPC (One Laptop Per Child) un proyecto en el que se
le permite a los niños mediante un portátil de bajo costo enseñarles a
incorporarse a la tecnología sin necesidad de tener grandes recursos pudo crecer
y seguir manteníendose como una alternativa educativa también para l@s más
peques de la casa.
Sugar es un entorno de escritorio que nació con el objetivo de crear una
interfaz muy intuitiva para aquell@s niñ@s que no podían acceder a la tecnología
puntera de países del primer mundo. Creada por Sugar Labs en mayo del 2016,
como entorno para el proyecto OLPC (One Laptop Per Child) un proyecto en el que se
le permite a los niños mediante un portátil de bajo costo enseñarles a
incorporarse a la tecnología sin necesidad de tener grandes recursos pudo crecer
y seguir manteníendose como una alternativa educativa también para l@s más
peques de la casa.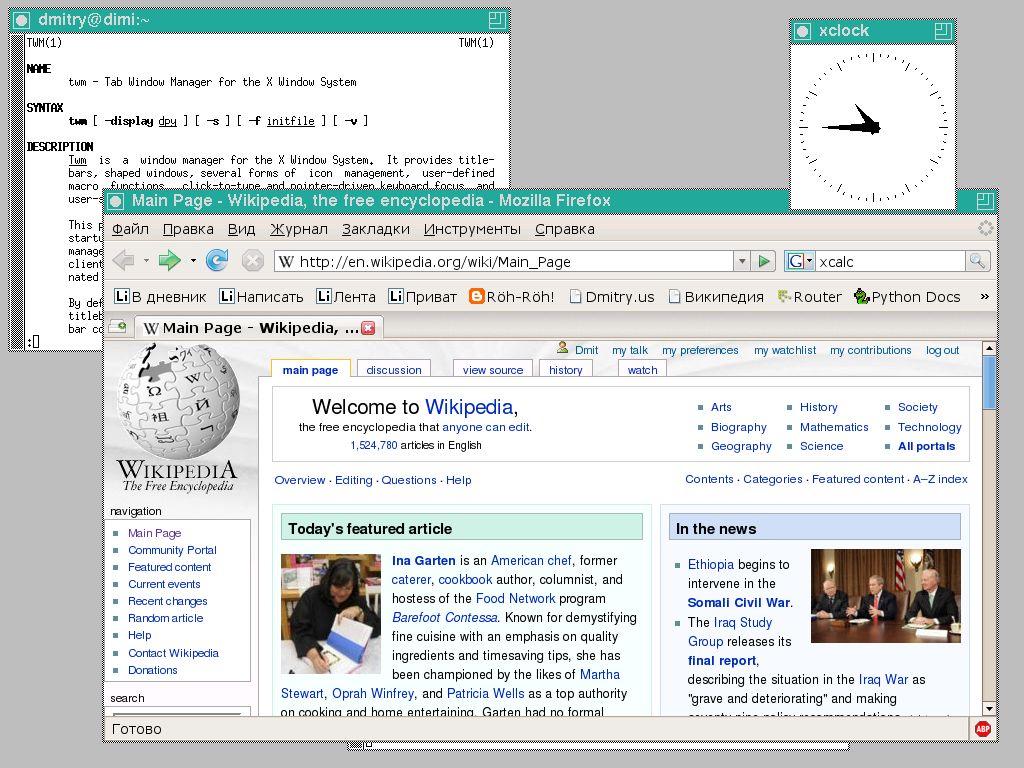 Tab Window Manager, es el gestor de ventanas más común en todo Linux. Fue desarrollado por Tom LaStrange desde 1987, el nombre original estaba basado en la siglas de su nombre Tom's Window Manager, pero el X Consortium lo adoptó y lo renombró en 1989. En TWM se pueden apilar las ventanas, las cuáles contienen título, e iconos para interactuar. Este gestor de ventana suele utilizarse con programas como un reloj analógico
Tab Window Manager, es el gestor de ventanas más común en todo Linux. Fue desarrollado por Tom LaStrange desde 1987, el nombre original estaba basado en la siglas de su nombre Tom's Window Manager, pero el X Consortium lo adoptó y lo renombró en 1989. En TWM se pueden apilar las ventanas, las cuáles contienen título, e iconos para interactuar. Este gestor de ventana suele utilizarse con programas como un reloj analógico 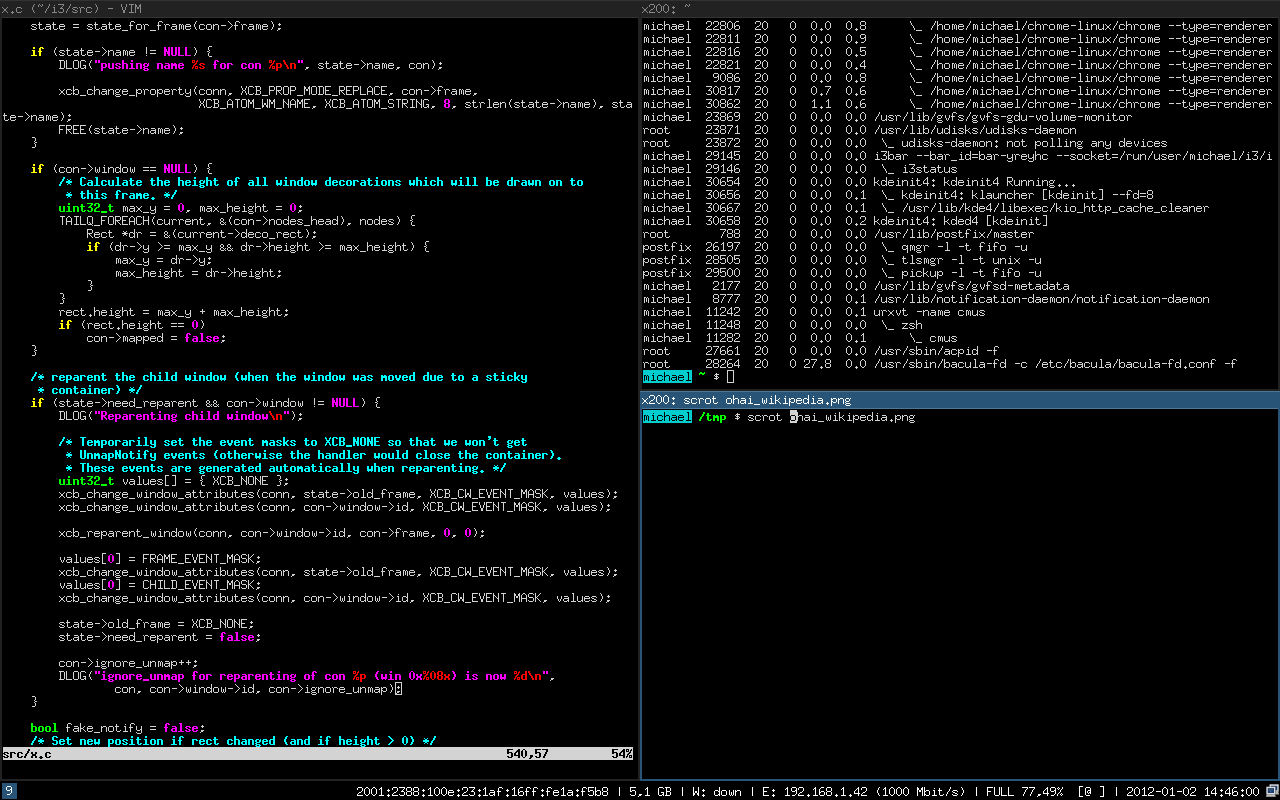 i3wm o también conocido como i3, es un gestor de ventanas que no se superposiciona, simplemente se adapta una ventana con la otra sin superponerse. i3 nos permite gestionar ventanas en modo stack es decir, apiladas, o bien en modo de pestañas tab entre más características. En suma, soporta modo multi-pantalla, está reescrita desde 0 estando todo su código licenciado bajo términos BSD. Hay que destacar que tiene soporte UTF-8 y es muy fácil de configurar. Su primera versión fue escrita en C por Michael Stapelberg el 15 de marzo del 2009.
i3wm o también conocido como i3, es un gestor de ventanas que no se superposiciona, simplemente se adapta una ventana con la otra sin superponerse. i3 nos permite gestionar ventanas en modo stack es decir, apiladas, o bien en modo de pestañas tab entre más características. En suma, soporta modo multi-pantalla, está reescrita desde 0 estando todo su código licenciado bajo términos BSD. Hay que destacar que tiene soporte UTF-8 y es muy fácil de configurar. Su primera versión fue escrita en C por Michael Stapelberg el 15 de marzo del 2009.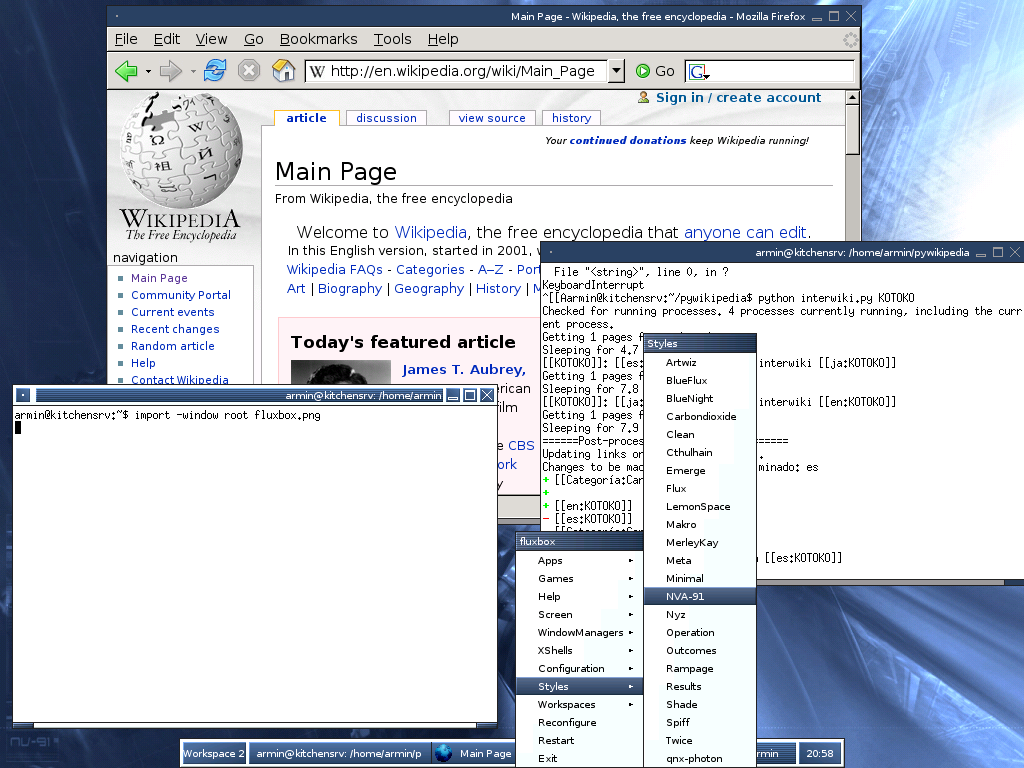 Fluxbox es un gestor de ventanas creado por Henrik Kinnunen el 12 de septiembre de 2001. Es un wm muy sencillo y fácil de usar, bastante ligero en cuanto consumo y rendimiento. Está basado en un gestor de ventanas llamado Blackbox ya desmantenido. La última versión liberada es la 1.3.7 publicada el 8 de febrero de 2015.
Fluxbox es un gestor de ventanas creado por Henrik Kinnunen el 12 de septiembre de 2001. Es un wm muy sencillo y fácil de usar, bastante ligero en cuanto consumo y rendimiento. Está basado en un gestor de ventanas llamado Blackbox ya desmantenido. La última versión liberada es la 1.3.7 publicada el 8 de febrero de 2015.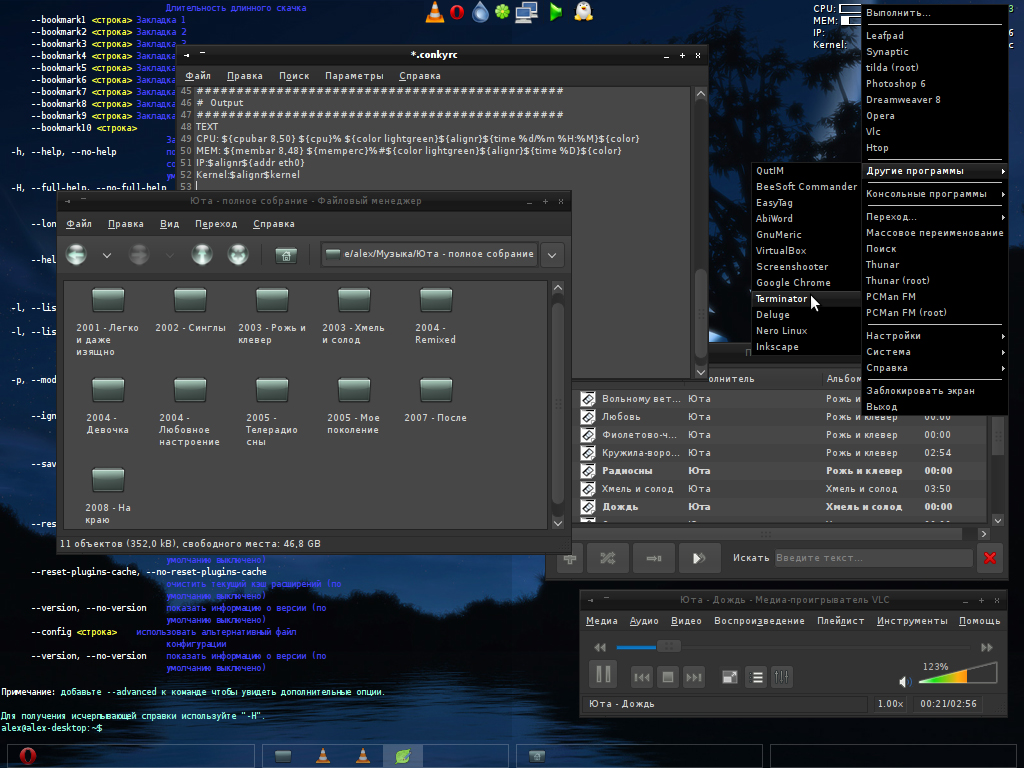 Openbox es otro gestor de ventanas creado por Dana Jansens y Mikael Magnusson el 18 de septiembre de 2002. Este también derivó de sus inicios de Blackbox, sin embargo, ha sido reescrito totalmente desde la versión 3.0. Este gestor sacrifica entre otras cosas algunas funciones típicas como la barra de menú, lista de apps en ejecución o bordes redondeados en las ventanas. No obstante, posee herramientas de configuración del entorno bastane útiles para cambiar el fondo de pantalla, tema del gestor...etc, no obstante, el gestor de ventanas lleva sin desarrollarse desde el 1 de julio del 2015.
Openbox es otro gestor de ventanas creado por Dana Jansens y Mikael Magnusson el 18 de septiembre de 2002. Este también derivó de sus inicios de Blackbox, sin embargo, ha sido reescrito totalmente desde la versión 3.0. Este gestor sacrifica entre otras cosas algunas funciones típicas como la barra de menú, lista de apps en ejecución o bordes redondeados en las ventanas. No obstante, posee herramientas de configuración del entorno bastane útiles para cambiar el fondo de pantalla, tema del gestor...etc, no obstante, el gestor de ventanas lleva sin desarrollarse desde el 1 de julio del 2015.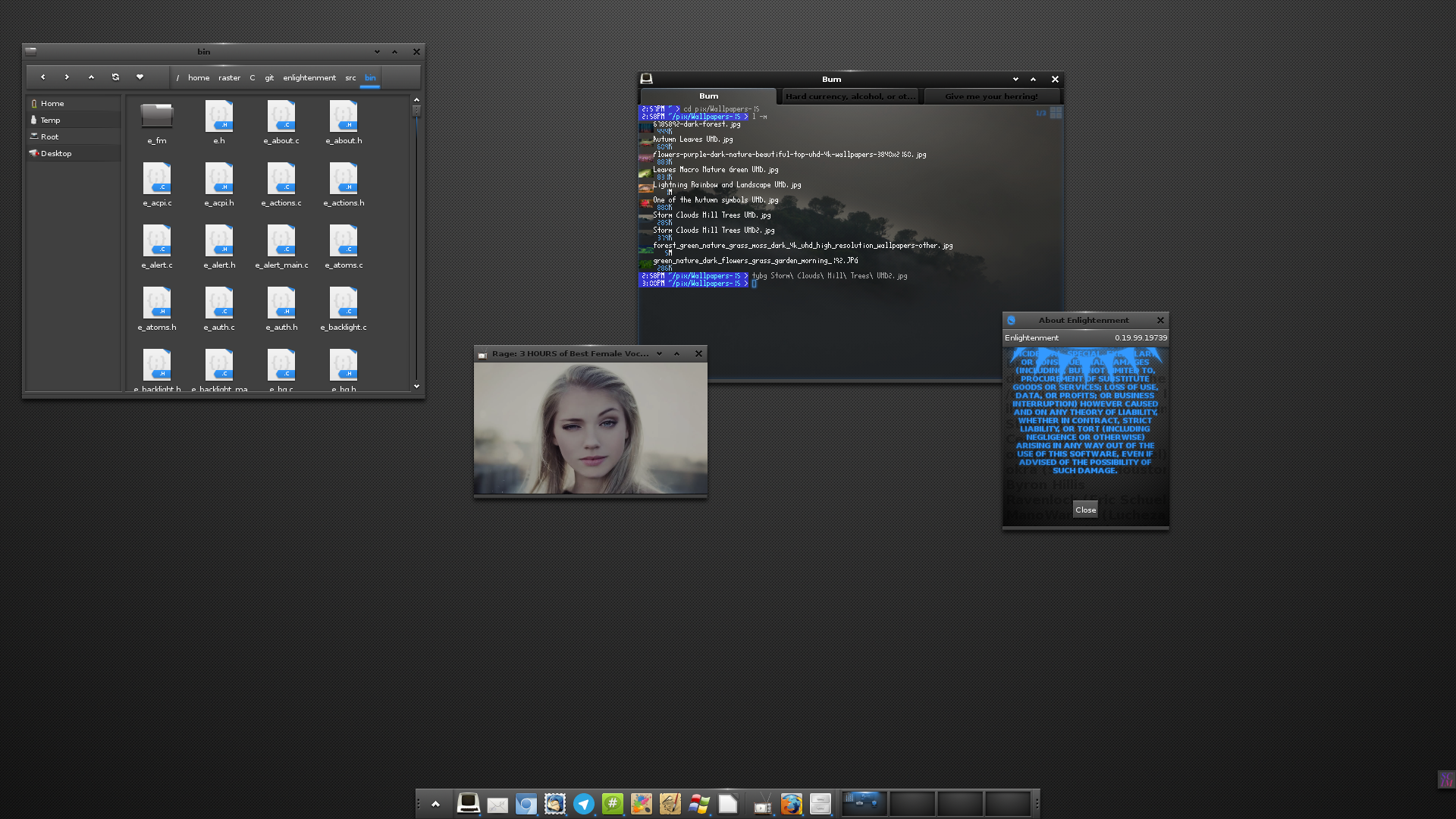 Es un gestor de ventanas con una gran cantidad de applets, módulos y aplicaciones que lo intentan convertir en un entorno de escritorio completo, la primera versión liberada fue en 1997 por Rasterman (Carsten Haitzler), mientras que la última versión liberada fue el 15 de marzo de 2018. Enlightenment lleva un desarrollo lento y denso que hace que el entorno sea un poco menos novedoso y no todos sus módulos y applets están bien recibidos según que distribuciones. Suelen faltar muchos de ellos, y algunas veces las compilaciones de los mismos no suelen llevar a resultados favorables. No obstante es una buena alternativa para aquellas personas que busquen un estado intermedio entre gestor y entorno, y resulta muy liviano y con una imagen un tanto futurista.
Es un gestor de ventanas con una gran cantidad de applets, módulos y aplicaciones que lo intentan convertir en un entorno de escritorio completo, la primera versión liberada fue en 1997 por Rasterman (Carsten Haitzler), mientras que la última versión liberada fue el 15 de marzo de 2018. Enlightenment lleva un desarrollo lento y denso que hace que el entorno sea un poco menos novedoso y no todos sus módulos y applets están bien recibidos según que distribuciones. Suelen faltar muchos de ellos, y algunas veces las compilaciones de los mismos no suelen llevar a resultados favorables. No obstante es una buena alternativa para aquellas personas que busquen un estado intermedio entre gestor y entorno, y resulta muy liviano y con una imagen un tanto futurista.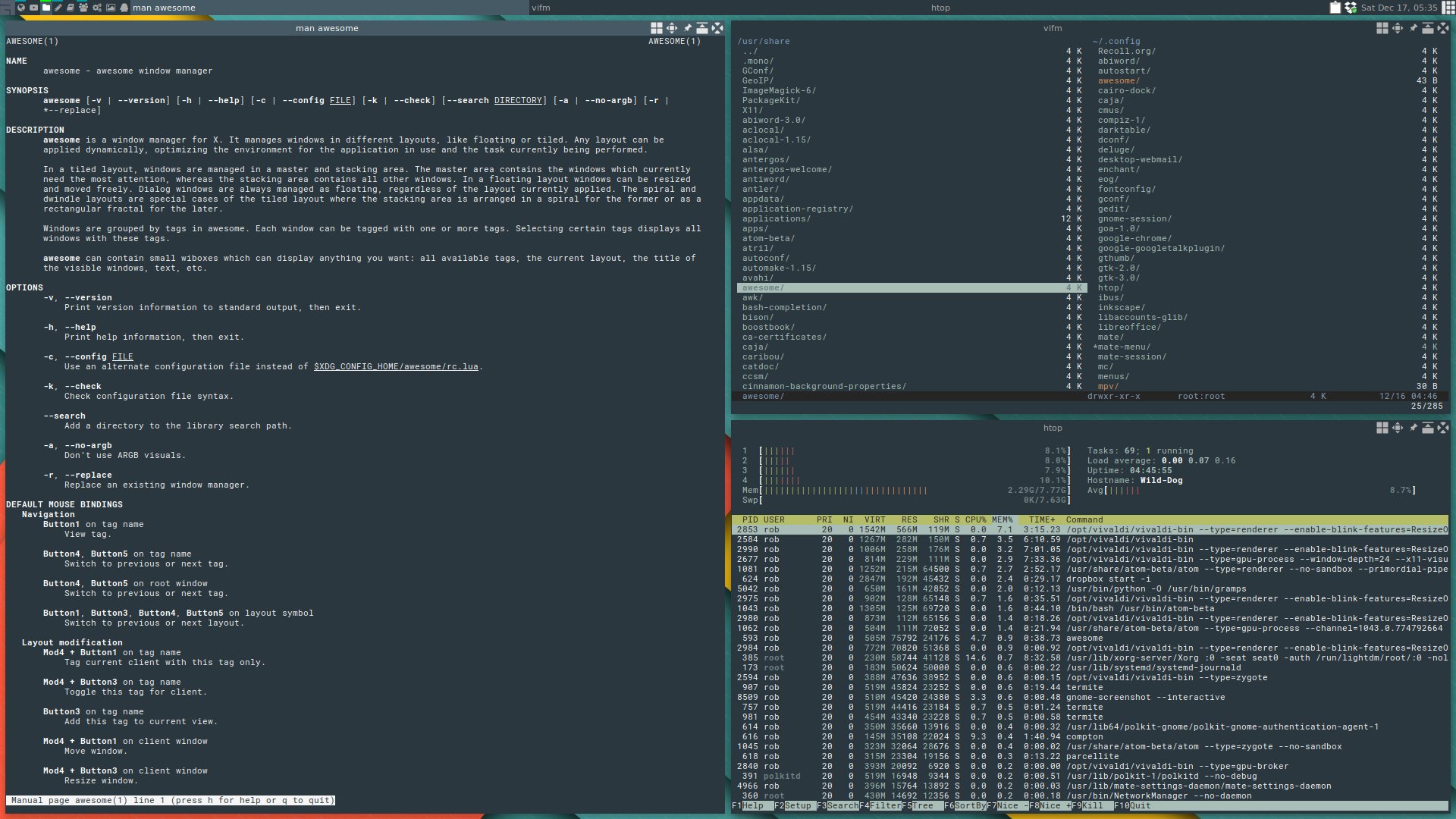 Otro gestor de ventanas elaborado en C y en Lua, también es parecido a i3 en el que no es necesario hacer uso de ningún tipo de ratón y permite acoplar fácilmente las ventanas entre sí. La primera versión fue liberada el 18 de septiembre del 2007 por Julien Danjou, siendo un fork de dwm. En algunas distribuciones se encuentra disponible, pero desde el 25 de septiembre del 2016 se encuentra desmantenido.
Otro gestor de ventanas elaborado en C y en Lua, también es parecido a i3 en el que no es necesario hacer uso de ningún tipo de ratón y permite acoplar fácilmente las ventanas entre sí. La primera versión fue liberada el 18 de septiembre del 2007 por Julien Danjou, siendo un fork de dwm. En algunas distribuciones se encuentra disponible, pero desde el 25 de septiembre del 2016 se encuentra desmantenido.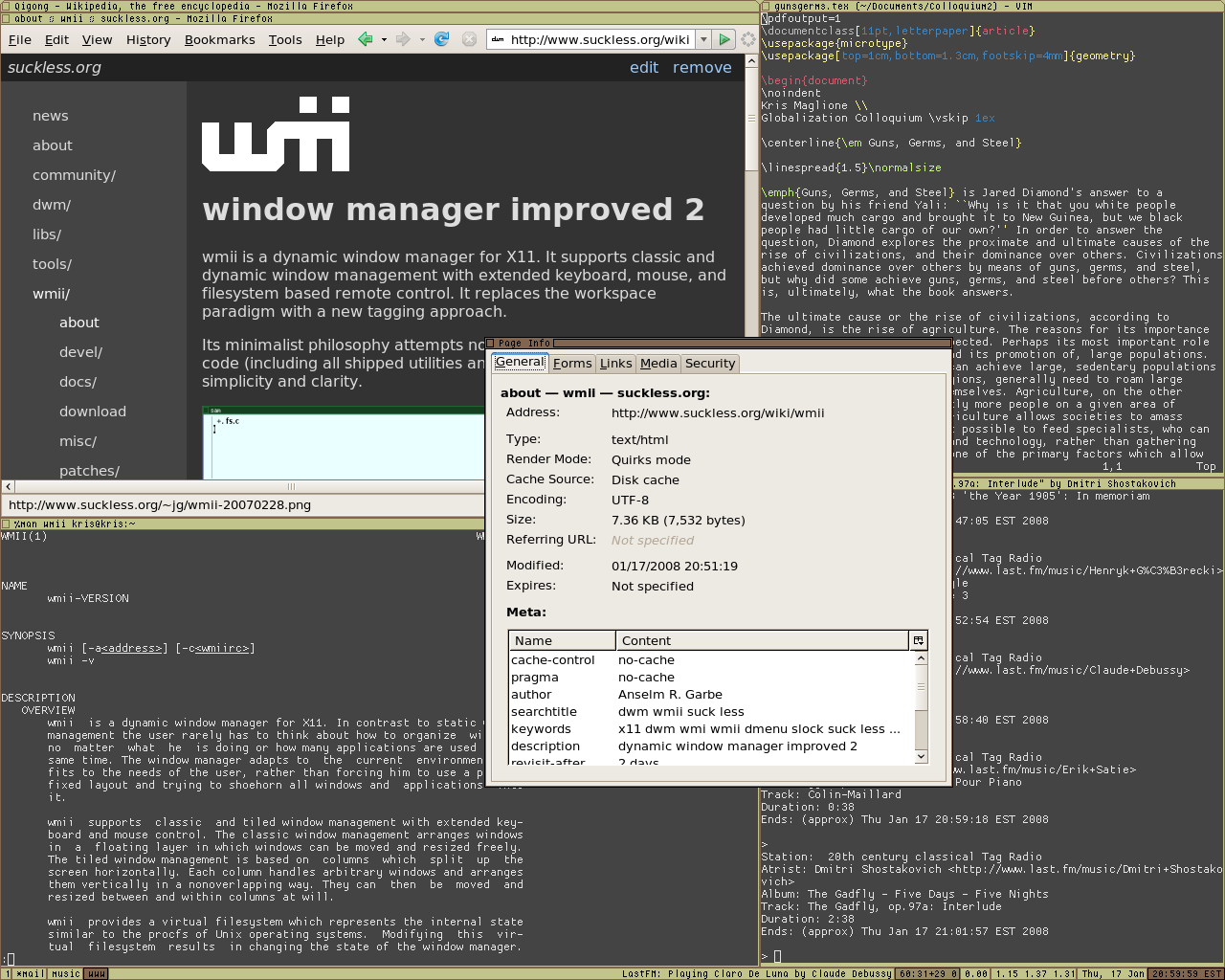 Windows Manager Improved 2, es un gestor de ventanas que soporta el manejo de ventanas con ratón o teclado elaborado por Anselm R. Garbe y Kris Maglione y viendo la luz por primera vez el 1 de junio de 2005, tiene una filosofía minimalista de no ir más allá de 10,000 líneas de código. La última versión estable fue liberada el 1 de julio del 2017.
Windows Manager Improved 2, es un gestor de ventanas que soporta el manejo de ventanas con ratón o teclado elaborado por Anselm R. Garbe y Kris Maglione y viendo la luz por primera vez el 1 de junio de 2005, tiene una filosofía minimalista de no ir más allá de 10,000 líneas de código. La última versión estable fue liberada el 1 de julio del 2017.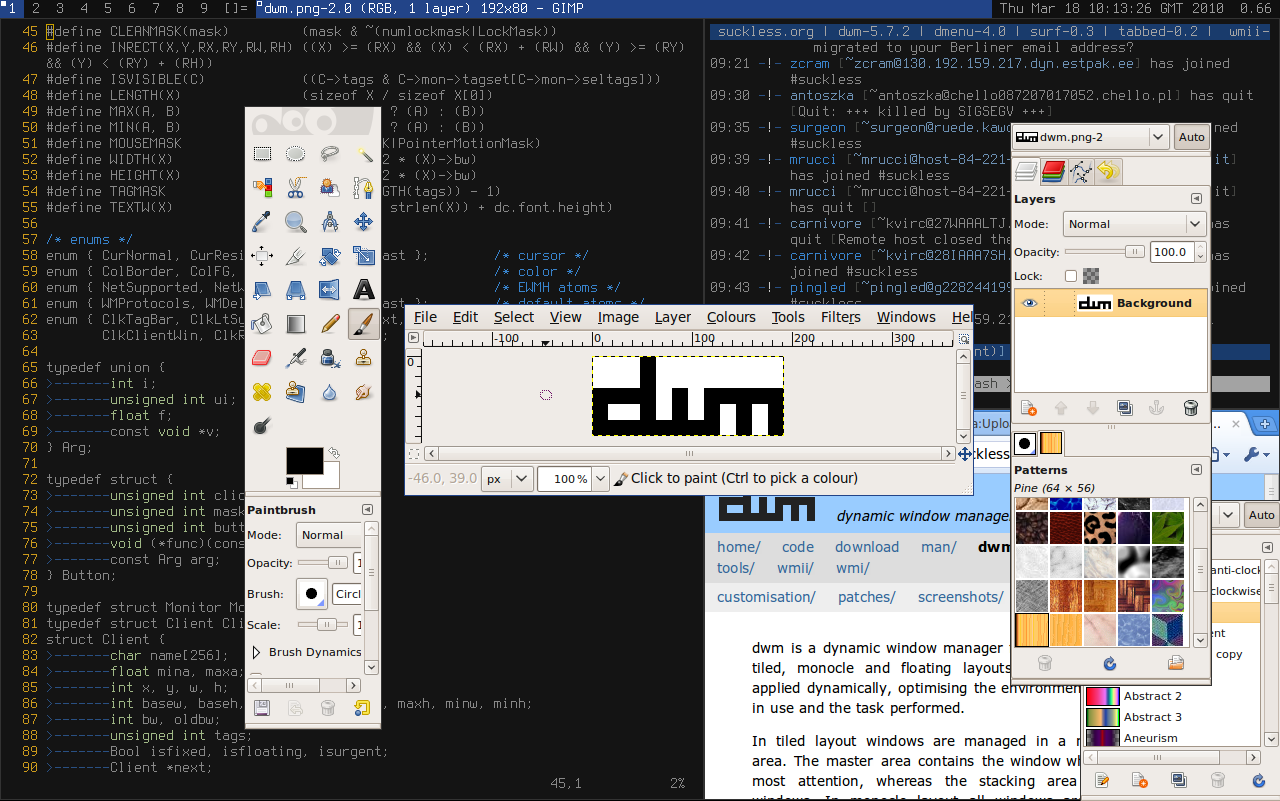 Es otro gestor de ventanas desarrollado por Anselm R. Garbe y liberándolo el 14 de julio de 2006. Es un wm muy minimalista pareciéndose a wmii, sin embargo, es mucho más simple que este último y está escrito en puro C para tener un rendimiento mucho más elevado además de añadir seguridad al código, pero este muy conocido gestor de ventanas se quedó en desarrollo al igual que wmii, el 1 de julio de 2017.
Es otro gestor de ventanas desarrollado por Anselm R. Garbe y liberándolo el 14 de julio de 2006. Es un wm muy minimalista pareciéndose a wmii, sin embargo, es mucho más simple que este último y está escrito en puro C para tener un rendimiento mucho más elevado además de añadir seguridad al código, pero este muy conocido gestor de ventanas se quedó en desarrollo al igual que wmii, el 1 de julio de 2017. {.size-full}
{.size-full}